PostgreSQL is a powerful RDBMS which can store data as well as do some manipulations on it such as search or calculating some analytical information and one the techniques is FTS. The Full Text Search (or FTS for short) was introduced in PostgreSQL firstly as a tsearch extension and added into PostgreSQL 8.3 as a core feature. Unfortunately, since PostgreSQL 8.3 FTS almost didn’t change and have some issues which were detected during years of the work with it. I’m working on a patch to extend the abilities and flexibility of FTS configuration mechanism in PostgreSQL and want to describe it in more details in this post.
Basics of Full Text Search
First of all, let’s take a look at theory of FTS and its concepts.
FTS is a set of techniques to process text written in a natural language in order to do a search over documents with respect to language structure and rules.
The most important parts of text processing are dividing the text into words (tokens) and normalize them.
Most of the languages have some ways to generate one word from another by adding prefixes and suffixes to change the part of speech or slightly change the meaning or meet some grammar rule.
However, the word didn’t change the root and still have the similar meaning.
The example of the normalization is transforming word jumps to jump or change processed to process.
The normalization allows us to search for any form of one word.
One more concept of the FTS which is worth mention is stopwords. Stopword is a word which is too common in a language and can be found in most of the documents. A good example of stopwords are articles, conjunctions, and particles. Common way to work with stopwords is to ignore them because a query with stopword probably will return all documents.
Current Way to Configure FTS in PostgreSQL
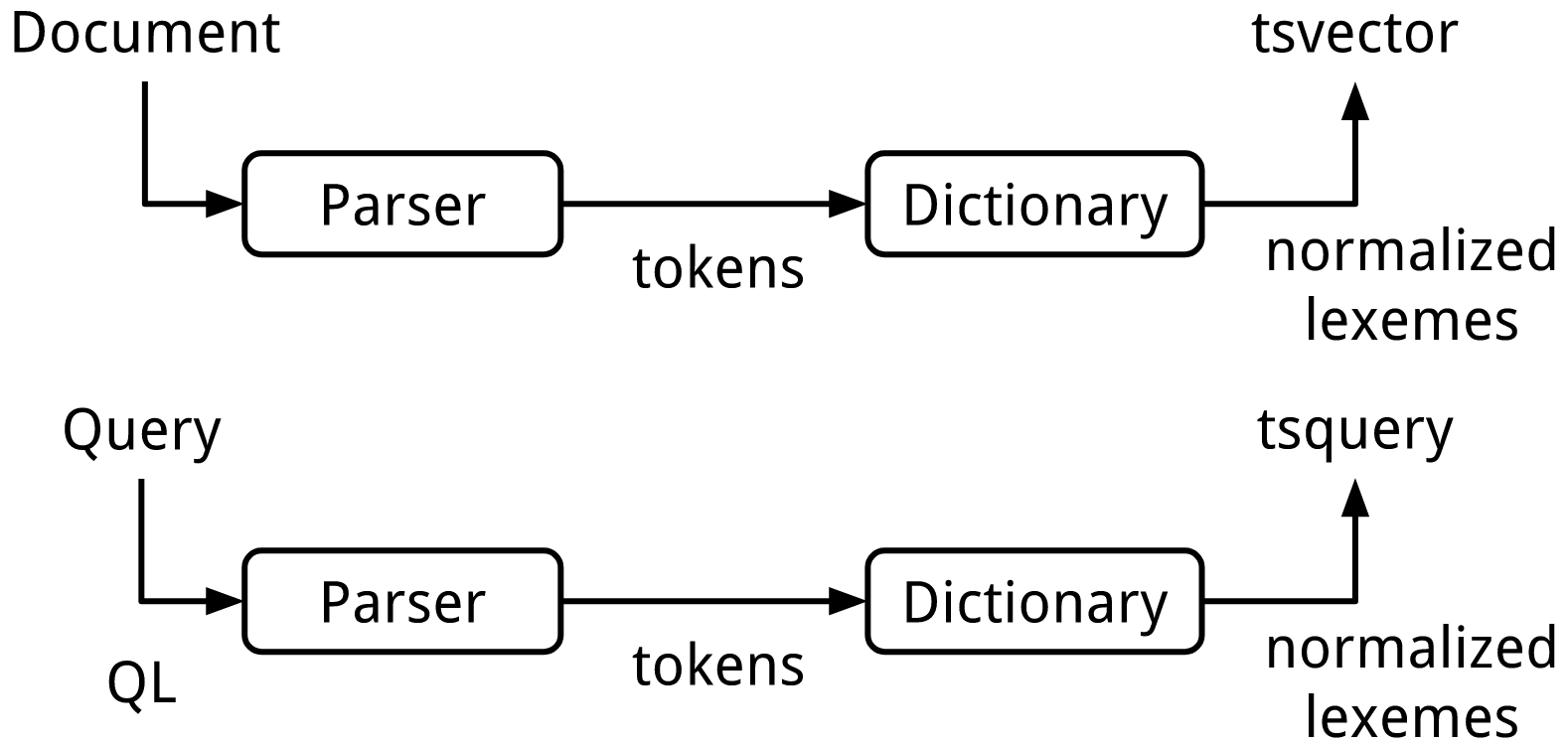
FTS model in PostgreSQL is shown in the following schema.

The type tsvector is a representation of the document ready for FTS and tsquery is a representation of the search query.
Both types contain lexemes with some additional information such as positions or query operators.
Objects of both types are generated in a similar way, except parsing of query language during generation of tsquery.
The parser and dictionaries steps are same for both.
A parser is a software which divides a text into tokens and sends it to dictionaries, while dictionaries process each token to generate lexemes which will be used after the processing.
An FTS configuration describes which parser and dictionaries use to process a text.
Parser defines a list of possible token types.
Each token type has it’s own dictionaries configuration Dictionaries are written in a chain and called one by one from left to right.
The first non-NULL output will be used as an output of the whole chain (except TSL_FILTER case).
Full Text Search Problems
Multilingual Search
One of the most common problems with FTS in PostgreSQL is the inability to process set of documents in different languages or a document which contains text in more than one language. The current way to solve the problem is to do a search in both languages separately and combine results. But this approach has few drawback such as storing redundant data in indices and complexity of ranking of the results. Here is one of the threads in pgsql mailing list with the discussion of the problem.
Morphological and Exact Search
Another common problem is a combination of morphological and exact search in one query. The morphological search is a search with respect to words structure and grammar rules as it was described in “Basics of Full Text Search”. On the other hand, in exact search, we shouldn’t change the form of the word. It may be useful to do a query with a special term of a name inside.
Currently, it can be managed only by a combination of few tsquery/tsvector pairs and it’s hard to provide a user-friendly interface to it.
Special Stopwords Procesing
Current FTS infrastructure doesn’t provide a way to configure stopwords processing. The stopwords processing should be implemented in each dictionary and we can’t use a special dictionary to work with stopwords or disable their processing in a dictionary (unless dictionary author adds such a parameter to it). Also, it makes dictionaries too complicated since each of them contains two functions and stopword filtering function is repeated in each dictionary.
Flexible Way to Configure FTS in PostgreSQL
The new approach to configure FTS based on an idea to add an ability to select how token should be processed according to an output of some dictionary expression and its mainly based on CASE/WHEN/THEN/ELSE syntax with some simplifications.
According to the patch, an FTS configuration (config) is one of the following formats:
dictionary_nameconfig { UNION | INTERSECT | EXCEPT | MAP } configCASE config WHEN [ NO ] MATCH THEN { KEEP | config } [ ELSE config ] END
UNION, INTERSECT, and EXCEPT are same as for any other sets.
Special operator MAP used to configure the behavior of filtering dictionary with any dictionary.
It passes output of the left hand expression to the right one.
If the left hand expression doesn’t return anything an original token used as input for right hand expression.
Visit updated documentation to get a more detailed description of the new syntax:
Currently links are broken.
Use cases
Bilingual Search
With new configurations of FTS bilingual search can be described in one configuration which will combine a result of dictionaries for both languages. The following configuration combines English and German dictionaries:
ALTER TEXT SEARCH CONFIGURATION multi_en_de
ALTER MAPPING FOR asciiword, word WITH
CASE english_hunspell WHEN MATCH THEN KEEP ELSE english_stem END
UNION
CASE german_hunspell WHEN MATCH THEN KEEP ELSE german_stem END;
With such configuration, we can search over a set of bilingual documents without language markers (or documents which contains both English and German).
In English:
WITH docs(id, txt) as (values (1, 'Das geschah zu Beginn dieses Monats'),
(2, 'with old stars and lacking gas and dust'),
(3, '25 light-years across, blown bywinds from its central'))
SELECT * FROM docs WHERE to_tsvector('multi_en_de', txt) @@ to_tsquery('multi_en_de', 'lack');
id | txt
----+-----------------------------------------
2 | with old stars and lacking gas and dust
And in German:
WITH docs(id, txt) as (values (1, 'Das geschah zu Beginn dieses Monats'),
(2, 'with old stars and lacking gas and dust'),
(3, '25 light-years across, blown bywinds from its central'))
SELECT * FROM docs WHERE to_tsvector('multi_en_de', txt) @@ to_tsquery('multi_en_de', 'beginnen');
id | txt
----+-------------------------------------
1 | Das geschah zu Beginn dieses Monats
Morphological and Exact Search
A combination of stemmer dictionary with simple may be used to mix search for an exact form of one word and linguistic search for others.
ALTER TEXT SEARCH CONFIGURATION exact_and_linguistic
ALTER MAPPING FOR asciiword, word WITH english_stem UNION simple;
And we can search for plural form of the word star:
WITH docs(id, txt) as (values (1, 'Supernova star'),
(2, 'Supernova stars'))
SELECT * FROM docs WHERE to_tsvector('exact_and_linguistic', txt) @@ (to_tsquery('simple', 'stars') && to_tsquery('english', 'supernovae'));
id | txt
----+-----------------
2 | Supernova stars
Special Stopwords Processing
With new configuration, it is possible to use a separate dictionary for a stopword detection and get rid of mixing two functions in one dictionary.
ALTER TEXT SEARCH CONFIGURATION stopword_separate
ALTER MAPPING FOR asciiword, word WITH CASE stopwords WHEN NO MATCH THEN stemmer END;
Filtering dictionary
The filtering dictionaries are used to do a preprocessing of the word before the main dictionary processing.
Currently, each filtering dictionary is designed to behave as a filter and there is no way to use it as a regular dictionary (unless you put it in the end of the chain) or use a regular dictionary as a filter.
E.g. we can reimplement thesaurus to take out the preprocessing of dictionaries from it to the configuration.
ALTER TEXT SEARCH CONFIGURATION multi_en_de
ALTER MAPPING FOR asciiword, word WITH english_stem MAP thesaurus;
Links
Discussion in pgsql-hackers (Everyone is welcome to participate in the discussion or do a review)
Last modified on 2018-02-20